写在前面 很久没有写博客了,编辑器也从VSCode 迁移到VSCodium ,很多配置都跟着没了。花了点时间重新部署Github Pages ,又重新配了一下clangd 什么的,简单地学一点点Vulkan 相关的东西。
不得不说现在的大模型真是越来越好用了,这篇博客也会用到大模型的,比如补充一些知识,帮我插入超链接什么的,纠正一些说法之类的。现在大家真是有一个很好的老师了,再也不用像苦行僧一样了。
这篇博客在Trae 中辅助写作完成。
许愿一个不用配环境的明天 Vulkan实际上是支持很多平台的,在多数编译型二进制语言中也是可以直接拿SDK里的lib链接的。这里我选用C语言,除了相比于Rust 和Zig 要方便许多,还有一个就是我比较熟这个东西。
编辑器用的是VSCodium,插件用的是Kylin Clangd,没有用插件自带的clangd,Github上的 clangd 22.1.0 。
clangd已经变得成熟许多了,现在它能直接读MinGW 的gcc输出的信息然后自动补全头文件依赖什么的。我的MinGW直接用的CLion 捆绑的,只添加bin目录就可以了。环境变量如下:
之后改一下VSC里的clangd路径就可以了。
然后需要下载一下Vulkan的SDK,这里 。
安装
这个额外组件可以什么都不选。
安装后的SDK如下,需要Include和Lib目录下的文件。
然后调一个c的简单项目,我这里用的xmake ,用CMake 也可以。注意如果是xmake要改一下toolchain指向MinGW的路径,在Windows上是默认选用MSVC的。
1 xmake f --toolchain=gcc --mingw=C:\App\JetBrains\CLion\bin\mingw
这个配置看喜好。
题外话,MSVC 套件可能是Windows平台上真正最好的编译器了,但是我不喜欢VS ,平时喜欢用CLion。所以如果要只下载MSVC不下载VS,可以去VS下载页找一个叫vs_BuildTools 的东西,只安装那个,然后组件只勾选MSVC和Windows Kits(如果不做Windows开发,连这个也不用)。这样就得到纯净的MSVC套件了。用x64 Native Developer Command Prompt启动命令行就可以用MSVC了。
然后下面是xmake的配置。
1 2 3 4 5 6 7 8 9 set_project("vulkan" )"mingw" )"app" )"binary" )"main.c" )"C:\\SDK\\VulkanSDK\\1.4.341.1\\Include" )"C:\\SDK\\VulkanSDK\\1.4.341.1\\Lib" )"vulkan-1" )
根目录新建一个.clangd文件,写入以下配置然后重启IDE,让clangd自动找头文件
1 2 CompileFlags: Add: [-IC:\SDK\VulkanSDK\1.4.341.1\Include ]
以上SDK目录不同自行处理。
看一下目录结构。
正文 关于Vulkan是什么 Vulkan 是一个跨平台的二维、三维图形与计算的应用程序接口(API),由科纳斯组织(Khronos Group) 在2015年的游戏开发者大会(GDC)上首次宣布,并在2016年正式发布。最早它曾被称为”下一代OpenGL行动”或”glNext”,后来基于AMD捐赠的Mantle API构建而成,最终成为了今天这个开放标准。
Vulkan的设计目标是解决OpenGL和Direct3D 11这些传统API在现代硬件上的瓶颈。过去的API是基于单核CPU时代的思路设计的,驱动层做了大量的隐式管理工作,虽然降低了开发者的入门门槛,但也带来了不小的CPU开销。而且OpenGL的状态机模型在多线程环境下表现并不理想,无法有效利用现代CPU的多核优势。
Vulkan在这方面做了彻底的改变,它是一个底层(Low-level)的显式API,把GPU的控制权更多地交给了开发者。简单来说就是驱动做更少的事情,开发者做更多的事情。虽然这意味着你要写更多的代码才能画出第一个三角形,但换来的是更低的CPU开销、更直接的GPU控制,以及更好的多线程支持。从PC和游戏主机到手机和嵌入式设备,Vulkan几乎覆盖了所有主流平台,也是Android系统级别支持的图形API之一。
Vulkan还有一个很有意思的特点是它的着色器系统。传统API如OpenGL使用GLSL这样的高级着色语言,驱动在运行时需要编译着色器代码。而Vulkan采用的是SPIR-V (Standard Portable Intermediate Representation),一种中间二进制格式。你提前把着色器编译成SPIR-V,驱动只需要把它翻译成GPU的机器码就行了。这样做的好处是加载速度更快、更稳定,也不会出现以前那种”同样一份GLSL代码,在不同的显卡上表现不一样”的尴尬情况。
总之, Vulkan可以让你极大地控制GPU,甚至达到cuda/cuBLAS的性能。
我的实战是跟着教学写一个简单的Vulkan着色器,视频链接
实战
Vulkan供有点:Vulkan开发通常是沿着 “资源创建 → 配置绑定 → 提交执行 → 读取结果 → 销毁”的主线逐段推进。每遇到一个 vkCreate*,就要记住对应的 vkDestroy* 的位置;每遇到一个 vkAllocate*,就有对应的 vkFree*。Vulkan 的显式性意味着没有”自动回收”,一切生命周期必须手动管理。
1. 头文件与类型别名 引入 SDK 提供的 <vulkan/vulkan.h>,再定义一套趁手的类型缩写,减少后续代码的噪音。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdbool.h> #include <stddef.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <vulkan/vulkan.h> typedef uint8_t u8;typedef uint32_t u32;typedef uint64_t u64;#define ALIGN_UP(n, a) (((n) + (a) - 1) - (((n) + (a) - 1) % (a))) typedef uint32_t b32;typedef float f32;
<vulkan/vulkan.h> 是 Vulkan SDK 提供的唯一入口头文件 ,包含了所有类型、函数声明和扩展。u8/u32/u64 缩写:Vulkan API 大量使用 uint32_t 等定长类型,缩写能显著减轻视觉负担。ALIGN_UP 宏:将 n 向上对齐到 a 的整数倍。后面内存分配时会用到,因为不同硬件对缓冲区起始地址有对齐要求(通常 64–256 字节不等)。b32 是“布尔型 32 位”的缩写:在需要传入布尔量到结构体字段时,用 u32 比 C 的 bool 更明确地表达了 Vulkan 的结构体对齐语义。
2. main 入口与验证层检测 Vulkan 的 main 函数通常很长,但结构清晰。
从变量声明和验证层开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 int main () const char * validation_layer_name = "VK_LAYER_KHRONOS_validation" ;false ;NULL ; #ifndef NDEBUG 0 ;NULL ); malloc (sizeof (VkLayerProperties) * num_layers);for (u32 i = 0 ; i < num_layers; i++) {if (strcmp (layer_props[i].layerName, validation_layer_name) == 0 ) {true ;break ;free (layer_props);if (use_validation_layer) {1 ;#endif NULL , &instance);
逐行解释(关联上下文中距较远的语句一并说明):
代码行/段
说明
const char* validation_layer_nameVulkan 标准验证层名。VK_LAYER_KHRONOS_validation 是 Khronos 官方提供的调试层 ,非发布构建下用 #ifndef NDEBUG 控制。
VkInstance instance = NULLVkInstance ——Vulkan 顶层对象,托管驱动连接、物理设备枚举。末尾 vkDestroyInstance 与它远距配对 。
VkInstanceCreateInfo + VkApplicationInfo创建对象的标准模式:填 *CreateInfo 结构体,.sType 标明结构类型。
vkEnumerateInstanceLayerProperties(&num_layers, NULL)两段式枚举 (Vulkan 通用模式):第一段传 NULL 获取数量;第二段分配数组后再调拿到数据。
strcmp 循环查找遍历层列表匹配 VK_LAYER_KHRONOS_validation。
ppEnabledLayerNamesppEnabledLayerNames 类型是 const char* const*,需取字符串指针的地址。
vkCreateInstance三个参数:CreateInfo 指针、分配器回调(NULL=默认)、输出句柄指针。
3. 选择物理设备(VkPhysicalDevice)
VkPhysicalDevice 代表实际 GPU 硬件。用枚举+查询属性确认”在用哪块卡”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 NULL ;1 ;0 printf ("Using Device: %s\nDevice Type: %u\nVender ID: %u\nDriver Verison: " "%u\n" ,
逐行解释:
代码行/段
说明
num_physical_devices = 1告诉 Vulkan”最多取 1 个”。函数返回后该变量变为实际获取数。
vkEnumeratePhysicalDevices从 Instance 枚举设备句柄,同样两段式。
VkPhysicalDeviceProperties = { 0 }零初始化结构体。C 中 {0} 是零初始化写法,避免未初始化的垃圾值。
vkGetPhysicalDeviceProperties读取 deviceName、vendorID(NV=0x10DE)、driverVersion、deviceType。
printf打印设备信息,验证选到的 GPU 是否符合预期。
4. 创建逻辑设备(VkDevice)
VkDevice 类比 OpenGL 的 Context。创建前需确定队列族(Queue Family) ——不同队列族提供不同功能(图形/计算/传输)。做计算找 VK_QUEUE_COMPUTE_BIT。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 0 ;NULL ;0 ;NULL );malloc (sizeof (VkQueueFamilyProperties) * queue_family_count);for (u32 i = 0 ; i < queue_family_count; i++) {if (queue_family_properties[i].queueFlags & VK_QUEUE_COMPUTE_BIT) {break ;free (queue_family_properties);0.0f ;1 ,1 ,#ifndef NDEBUG if (use_validation_layer) {1 ;#endif NULL , &device);
逐行解释:
代码行/段
说明
queue_family_index = 0存储匹配到的队列族编号。
vkGetPhysicalDeviceQueueFamilyProperties两段式枚举队列族属性,包含 queueFlags(能力位掩码)和 queueCount。
VK_QUEUE_COMPUTE_BIT 遍历找支持计算能力的队列族。break 取第一个匹配项。
f32 priority = 0.0f队列优先级 0.0~1.0,单队列时设为 0 即可。
VkDeviceQueueCreateInfo指定需要创建的队列数量(1 个)、族编号、优先级。
验证层条件编译
验证层需同时在 Instance 和 Device 级别激活。
vkCreateDevice创建逻辑设备。末尾 vkDestroyDevice 与此处远距配对 。
5. 创建缓冲区(VkBuffer)
VkBuffer 是显存缓冲区的逻辑句柄 ,不携带实际内存。内存需 vkAllocateMemory 另分,再用 vkBindBufferMemory 绑定。两个 VkBuffer 可以共享同一块 VkDeviceMemory 的不同偏移区域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 u32 vector_size = 16 ;sizeof (f32) * vector_size;NULL , out_buffer = NULL ;1 ,NULL , &in_buffer);NULL , &out_buffer);
逐行解释:
代码行/段
说明
vector_size = 16数组长度,GPU 对 16 个元素做并行加法。
buffer_size = sizeof(f32) * 16每个 float 4 字节 × 16 = 64 字节。
原注释”共享内存但是为输入输出创建单独的缓冲区”
两个 VkBuffer 句柄 → 同一块 VkDeviceMemory 的不同偏移。
VK_BUFFER_USAGE_2_STORAGE_BUFFER_BIT标记为 Storage Buffer(SSBO) ,计算着色器可读写。Vulkan 1.3 新枚举(等价旧版无 _2)。
VK_SHARING_MODE_EXCLUSIVE独占模式:缓冲区只被一个队列族使用,简单且性能好。
两次 vkCreateBuffer
同样 CreateInfo 创建 in/out 两个句柄。此刻内存尚未分配 。
6. 内存需求查询、对齐计算与分配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 0 }, out_mem_reqs = { 0 };0 ;0 };0 ;for (u32 i = 0 ; i < mem_properities.memoryTypeCount; i++) {if ((mem_properities.memoryTypes[i].propertyFlags & VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT) && (mem_properities.memoryTypes[i].propertyFlags & VK_MEMORY_PROPERTY_HOST_COHERENT_BIT)) {break ;NULL ;NULL , &memory);
逐行解释:
代码行/段
说明
vkGetBufferMemoryRequirements查询对齐要求:size(实际字节数,可能>buffer_size)、alignment(对齐边界)、memoryTypeBits(位掩码)。
ALIGN_UP(in_mem_reqs.size, out_mem_reqs.alignment)让 out_buffer 从已对齐位置开始,两缓冲区不重叠且各自对齐。
VK_MEMORY_PROPERTY_HOST_VISIBLE | HOST_COHERENTHost-Visible + Host-Coherent :CPU 可访问(map),且无需手动 flush。
vkAllocateMemory分配物理显存。VkDeviceMemory 是实际显存块句柄,与 VkBuffer 分离,通过 vkBindBufferMemory 关联。
7. 内存映射、写入数据、解除映射 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 {NULL ; 0 , total_size, 0 , (void **)(&data));sizeof (f32)); for (u32 i = 0 ; i < vector_size; i++) {1 ;
代码行/段
说明
vkMapMemory将显存映射到 CPU 地址空间,(void**)(&data) 输出 CPU 可读写的指针。
out_data = data + (out_buffer_offset / sizeof(f32))指针算术跳到输出缓冲区。除以 sizeof(f32) 得到 float 下标偏移。
填充数据
输入 [0..15],输出初始值 [15..0]。两者之和恒为 vector_size-1,便于验证 GPU 计算结果。
vkUnmapMemory解除映射。HOST_COHERENT 内存类型下数据自动写回显存。
8. 绑定缓冲区到内存 1 2 3 0 );
vkBindBufferMemory:将 VkBuffer 句柄与 VkDeviceMemory 关联。in_buffer 从偏移 0 开始,out_buffer 从已对齐的 out_buffer_offset 开始。
9. 加载着色器模块(VkShaderModule)
VkShaderModule 是 SPIR-V 字节码的薄包装,把 .spv 文件中的二进制数据交给 Vulkan 驱动。注意 GPU 机器码的编译要到管线创建时才发生,ShaderModule 可以提前销毁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 NULL ;"add.spv" , "rb" );0 , SEEK_END);0 , SEEK_SET);malloc (size);1 , size, file);NULL ,free (shader_file);
代码行/段
说明
fopen("add.spv", "rb")以二进制方式打开编译好的 SPIR-V 文件。.spv 是着色器预编译输出。
ftell / malloc / fread标准 C 读文件流程:获取大小→分配内存→读取。
u32* shader_file = (u32*)malloc(size)SPIR-V 规范要求按 uint32_t 对齐读取,因为 SPIR-V 指令是 32 位定长。但 fread 用 size(字节数)而非元素数,所以安全。
VkShaderModuleCreateInfo填入 codeSize(字节)和 pCode(指向 SPIR-V 数据的指针)。
vkCreateShaderModule创建着色器模块。注意 free(shader_file) 紧随其后——一旦创建成功,字节码已复制到驱动内部。
远距配对 末尾 vkDestroyShaderModule 与此处配对。
10. 描述集布局(Descriptor Set Layout)
Descriptor Set 是着色器与缓冲区之间的”接线板”。Layout 定义接口(几个 binding、各是什么类型),Descriptor Set 则是实际的绑定实例。这里着色器需要 3 个 Storage Buffer:binding=0 输入,binding=1 输出,binding=2 也是输出(原代码第 3 个 binding 指向 out_buffer)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 , VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1 , VK_SHADER_STAGE_COMPUTE_BIT,NULL },1 , VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1 , VK_SHADER_STAGE_COMPUTE_BIT,NULL },2 , VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1 , VK_SHADER_STAGE_COMPUTE_BIT,NULL }NULL ;sizeof (binding) / sizeof (binding[0 ]),NULL , &descriptor_set_layout);
代码行/段
说明
VkDescriptorSetLayoutBinding binding[3]定义 3 个绑定槽:binding=0/1/2,类型均为 STORAGE_BUFFER,在计算着色器阶段可见。
vkCreateDescriptorSetLayout创建布局。数量用 sizeof(binding)/sizeof(binding[0]) 避免硬编码。
11. 描述池与分配描述集
VkDescriptorPool 是描述集分配器,类似内存池。VkDescriptorSet 是 pool 中分配出的实际实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 VkDescriptorPool descriptor_pool = NULL ;1 ,1 ,sizeof (binding) / sizeof (binding[0 ]) },NULL ,NULL ;1 ,
代码行/段
说明
VkDescriptorPoolCreateInfomaxSets=1 最多分配 1 个描述集;descriptorCount=3 声明池中有 3 个 Storage Buffer 描述符的容量。
FREE_DESCRIPTOR_SET_BIT允许释放单个描述集。
vkAllocateDescriptorSets从 pool 中分配 1 个描述集,按 descriptor_set_layout 组织。
12. 写入描述集 —— 把缓冲区挂接到着色器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 VkWriteDescriptorSet write_set[] = {0 ,1 ,0 , .range = VK_WHOLE_SIZE } },1 , .descriptorCount = 1 ,0 , .range = VK_WHOLE_SIZE } },2 , .descriptorCount = 1 ,0 , .range = VK_WHOLE_SIZE } }sizeof (write_set) / sizeof (write_set[0 ]),0 , NULL );
代码行/段
说明
VkWriteDescriptorSet[3]将 in_buffer 写入 binding=0,out_buffer 写入 binding=1 和 2。VK_WHOLE_SIZE 表示整个缓冲区范围。descriptorType 必须与 Layout 声明一致。
vkUpdateDescriptorSets批量提交描述符写入。第四个参数 0 和第五个 NULL 表示没有 copy 操作(copy 用于描述集间迁移数据)。
13. 管线布局与管线(Pipeline Layout & Pipeline)
VkPipelineLayout 声明管线使用的描述集布局。VkPipeline 则把着色器模块、布局、管线状态打包成一个不可变对象。这里是计算管线,所以用 vkCreateComputePipelines。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 1 ,NULL ;NULL ,NULL ;"main" NULL , 1 , &compute_pipeline_create_info, NULL ,
代码行/段
说明
VkPipelineLayoutCreateInfo传入 descriptor_set_layout,告诉管线它用哪些描述集。
VkComputePipelineCreateInfo计算管线只需一个着色器阶段,pName = "main" 指定入口函数名。
vkCreateComputePipelines(device, NULL, ...)第二个参数是 PipelineCache ,可缓存编译结果跨次复用。传 NULL 表示不用缓存。
14. 命令池与命令缓冲区(Command Pool & Command Buffer)
VkCommandPool 是命令缓冲区的分配器。VkCommandBuffer 记录 GPU 要执行的指令。所有 vkCmd* 函数都是向命令缓冲区写入指令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 NULL ;NULL , &command_pool);NULL ;1 ,
代码行/段
说明
VkCommandPoolCreateInfo绑定到 queue_family_index——命令缓冲区只能提交到同族的队列。
VK_COMMAND_BUFFER_LEVEL_PRIMARY主缓冲区:可直接提交到队列。Secondary 只能被 Primary 调用。
15. 录制命令——4 步完成一次计算调度 1 2 3 4 5 6 7 8 9 10 0 , 1 , &descriptor_set, 0 , NULL );1 , 1 );
代码行/段
说明
vkBeginCommandBuffer开始录制。VkCommandBufferBeginInfo.flags 默认 0 表示一次性提交。
vkCmdBindPipeline绑定计算管线。VK_PIPELINE_BIND_POINT_COMPUTE 指定绑定目标是计算(非图形)。
vkCmdBindDescriptorSets将 descriptor_set 绑定到 set=0。参数含义:pipeline_layout、firstSet=0、1个set、&descriptor_set。
vkCmdDispatch(16, 1, 1)核心调用 :启动 16×1×1=16 个工作组,每个工作组的计算着色器负责一个数组元素。
vkEndCommandBuffer结束录制。至此命令缓冲区已包含 4 条指令,准备提交。
16. 提交与同步——让 GPU 跑起来
VkQueue 是实际执行命令的通道。VkFence 是 GPU→CPU 的同步信号——GPU 完成后发信号,CPU 在 vkWaitForFences 上等待。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 VkQueue queue = NULL ;0 , &queue );NULL ;NULL ,queue , 1 ,1 ,1 , &fence, true , ~(u64)(0 ));
代码行/段
说明
vkGetDeviceQueue从 Device 中获取队列句柄。第二个参数 0 取该族中的第 0 个队列。
vkCreateFence创建一个 Fence,初始状态 unsignaled。
VkSubmitInfo提交 1 个命令缓冲区,fence 在 GPU 完成所有命令后 signaled。
vkWaitForFences(..., ~(u64)(0))阻塞等待 直到 fence 信号。~(u64)(0) = UINT64_MAX:这是 C 语言中快速生成全 1 最大值的写法(等价 0xFFFFFFFFFFFFFFFF),表示无限等待。
17. 读取结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 NULL ;0 , total_size, 0 , (void **)(&data));sizeof (f32));printf ("in data : [" );for (u32 i = 0 ; i < vector_size; i++) {printf ("%2.0f " , in_data[i]);printf ("]\n" );printf ("out data : [" );for (u32 i = 0 ; i < vector_size; i++) {printf ("%2.0f " , out_data[i]);printf ("]\n" );
第二次 vkMapMemory:GPU 已将 in_data + out_initial 的结果写回 out_buffer。重新 map 读取指针。同一个 memory 对象、同样的偏移,返回的地址相同。
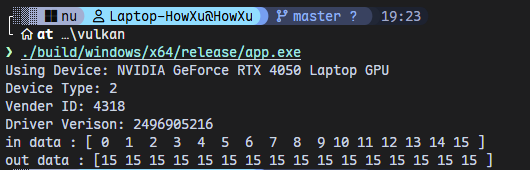
预期结果:out_data[i] = in_data[i] + out_data_old[i] = i + (16-1-i) = 15(每个元素都是 15)。
18. 资源清理——逆序销毁
Vulkan 没有垃圾回收。销毁顺序必须与创建顺序相反 :先销毁依赖其他资源的对象,最后销毁顶层对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vkDestroyFence(device, fence, NULL );NULL );NULL );NULL );1 , &descriptor_set);NULL );NULL );NULL );NULL );NULL );NULL );NULL );NULL ); return 0 ;
行
创建
销毁
注意
Fence
vkCreateFence (§16)vkDestroyFence
CommandPool
vkCreateCommandPool (§14)vkDestroyCommandPool会隐式销毁池中所有 CommandBuffer
Pipeline
vkCreateComputePipelines (§13)vkDestroyPipeline
PipelineLayout
vkCreatePipelineLayout (§13)vkDestroyPipelineLayout
DescriptorSet
vkAllocateDescriptorSets (§11)vkFreeDescriptorSets注意是 Free 不是 Destroy
DescriptorPool
vkCreateDescriptorPool (§11)vkDestroyDescriptorPoolflags 决定了能否 free 单个 set
ShaderModule
vkCreateShaderModule (§9)vkDestroyShaderModule
DeviceMemory
vkAllocateMemory (§6)vkFreeMemoryFree 不是 Destroy
Buffer
vkCreateBuffer (§5)vkDestroyBuffer×2(in + out)
Device
vkCreateDevice (§4)vkDestroyDevice
Instance
vkCreateInstance (§2)vkDestroyInstance最后一个销毁
运行测试 1 2 glslang add.comp.glsl -V -o add.spv # 编译着色器
运行结果:
结语 这个着色器用了400行代码,而且只实现了简单的向量加法功能。由此可见Vulkan真的是难度陡峭而且相当难写。但是好处也是很明显的,每个步骤都可以被显式的干预,更高的代码质量意味着更逆天的性能。希望有朝一日Vulkan也会有高等抽象的封装库或者框架。